Table of Contents
The Million-Dollar Infrastructure Decision
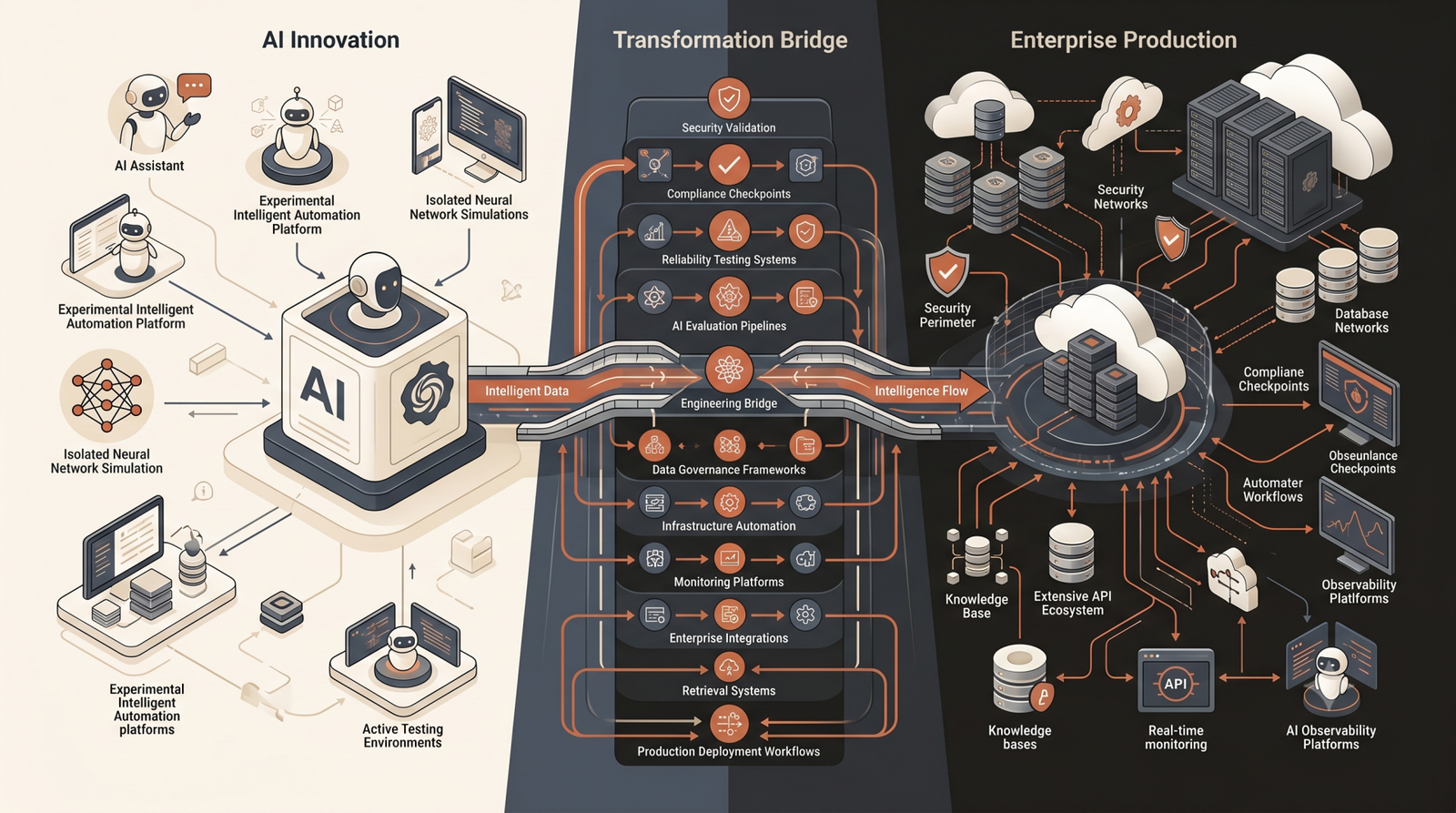
One of the most expensive mistakes an engineering team can make today is misunderstanding the boundary between data and behavior in language models. We frequently speak with founders and enterprise CTOs who are burning tens of thousands of dollars on GPU compute to fine-tune an open-source model, only to realize the system still hallucinates their internal company data. They approached an infrastructure problem with a training solution.
At Acadify Solution, we architect Kubernetes-scaled AI deployments for startups and enterprises. The foundation of a reliable AI system requires knowing exactly when to inject context dynamically via Retrieval-Augmented Generation (RAG) and when to permanently alter a model's weights through fine-tuning. Getting this right dictates your inference latency, your operational overhead, and your system's overall reliability.
RAG: Engineering for Dynamic Knowledge
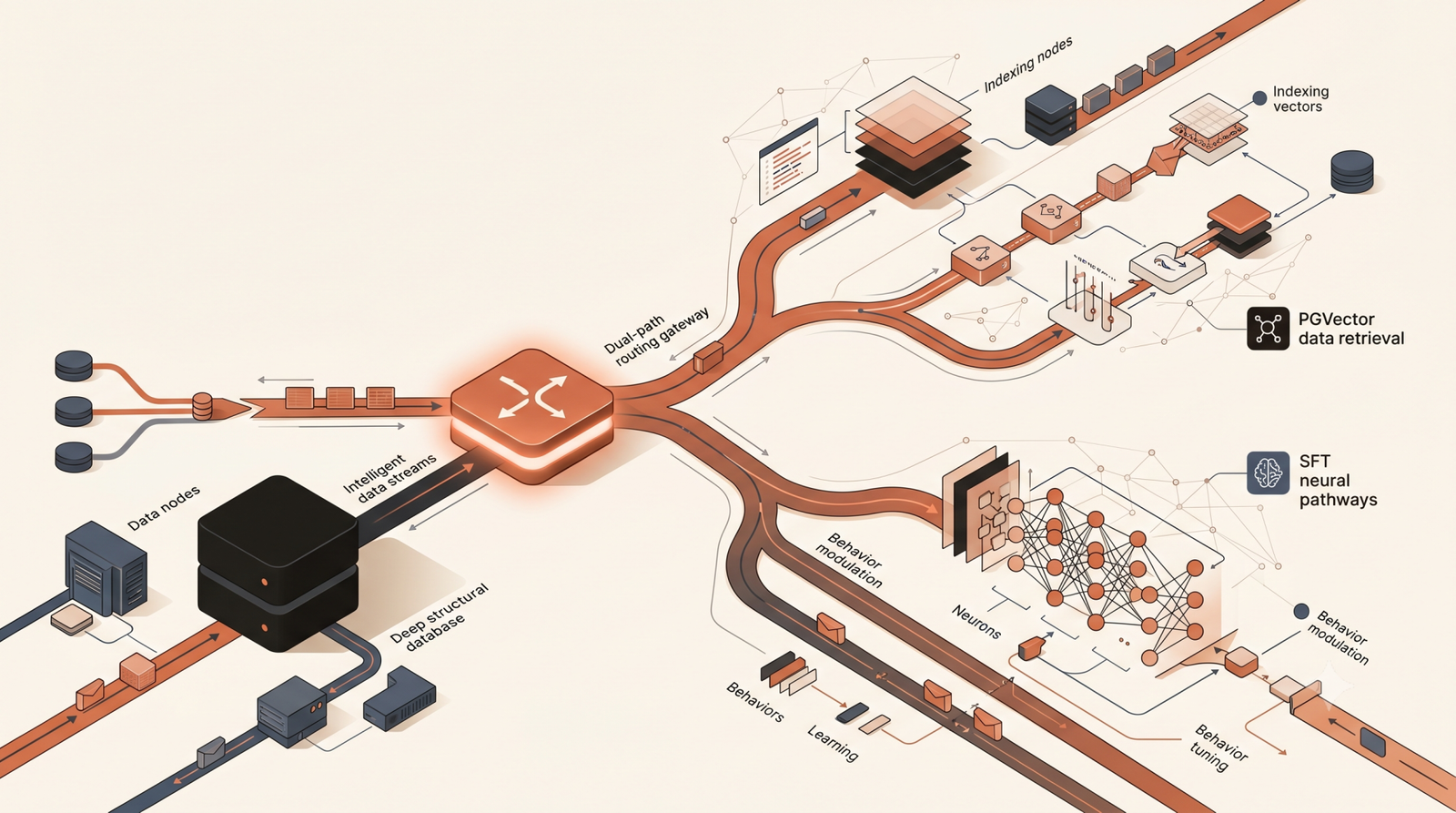
Retrieval-Augmented Generation is not about making a model smarter; it is about giving it a highly organized filing cabinet. If your application needs to answer questions based on proprietary, frequently updating, or user-specific data, RAG is the correct architectural choice.
Need MVP Development or AI Solutions?
Turn your idea into reality with Acadify. Fast, scalable, and built for enterprise growth.
In a production RAG pipeline, we do not rely on standard API wrappers. We deploy a microservices architecture where user queries are vectorized using specialized embedding models and mapped against a high-performance vector database like PGVector or Pinecone. A strict semantic reranking layer then filters the top-k results before pushing that specific context into the prompt of a frontier model like Anthropic Claude.
Use RAG when:
- Your data updates frequently (e.g., live financial documentation, daily support logs).
- You need strict access control where users can only query data they have permission to see.
- You need exact source attribution to prevent hallucination.
The operational advantage here is clear. Updating knowledge in a RAG system means simply writing a new row to a Postgres database. The LLM remains stateless, and your compute costs scale linearly with user traffic, not with the size of your dataset.
Fine-Tuning: Engineering for Specific Behavior
Fine-tuning is fundamentally about style, format, and behavior—not knowledge. If you want a model to consistently output valid JSON conforming to a rigid enterprise schema, or if you need an agent to perfectly mimic the terse, diagnostic tone of a senior network engineer, fine-tuning via QLoRA or standard SFT (Supervised Fine-Tuning) is required.
We see teams attempt to force behavioral changes through massive, paragraph-long system prompts. While prompt engineering works for prototypes, passing 2,000 tokens of strict instructional overhead with every single user query creates massive API bloat and increases latency. A properly fine-tuned model internalizes those instructions directly into its weights.
Use Fine-Tuning when:
- The model struggles to follow complex formatting rules despite deep prompting.
- You need to drastically reduce token usage by removing lengthy system instructions.
- The specific vernacular or reasoning style of your industry requires deep alignment.
Case Study: Re-Architecting a Healthcare SaaS Deployment
A mid-market healthcare analytics platform approached Acadify AI Labs after a failed product launch. Their internal team had spent two months fine-tuning an open-source 7B parameter model on their internal medical billing documentation. The result was a disaster. The model took 15 seconds to stream its first token, the GPU hosting costs on AWS were destroying their margins, and the system hallucinated billing codes that had been deprecated six months prior.
Our engineers stepped in and executed a total architectural pivot. We discarded the fine-tuned model and implemented a secure, HIPAA-compliant RAG pipeline. We ingested their documentation into a PGVector instance, paired it with a Redis caching layer for frequent queries, and routed the inference through the Anthropic Claude API.
By shifting the knowledge burden from the model weights to a scalable database, the outcomes were immediate. We reduced inference latency by 37%, allowing the UI to feel instantaneous. We lowered GPU compute spend by 42% because they were no longer maintaining idle VRAM for custom hosting. Most importantly, through our rigorous ASR (AI System Review) methodology, we validated a near-zero hallucination rate because the model was strictly constrained to the retrieved context.
Evaluation Determines Survival
Choosing between RAG and fine-tuning is only the first step. The true test of an enterprise system is how it degrades under pressure. You cannot deploy a complex RAG pipeline without a strict evaluation framework catching semantic drift, boundary violations, and retrieval failures.
Building production-grade AI is a brutal exercise in systems engineering. Prototypes forgive bad architecture; production destroys it. Whether you are scaling a specialized RAG pipeline or validating SFT traces for a custom model, your infrastructure must be designed for absolute reliability from day one. Companies that recognize AI as a deep infrastructure play scale effortlessly, while those treating it as a simple API integration remain stuck in a loop of broken demos.

No comments yet. Be the first to share your thoughts!