
Table of Contents
The Illusion of the Weekend Prototype
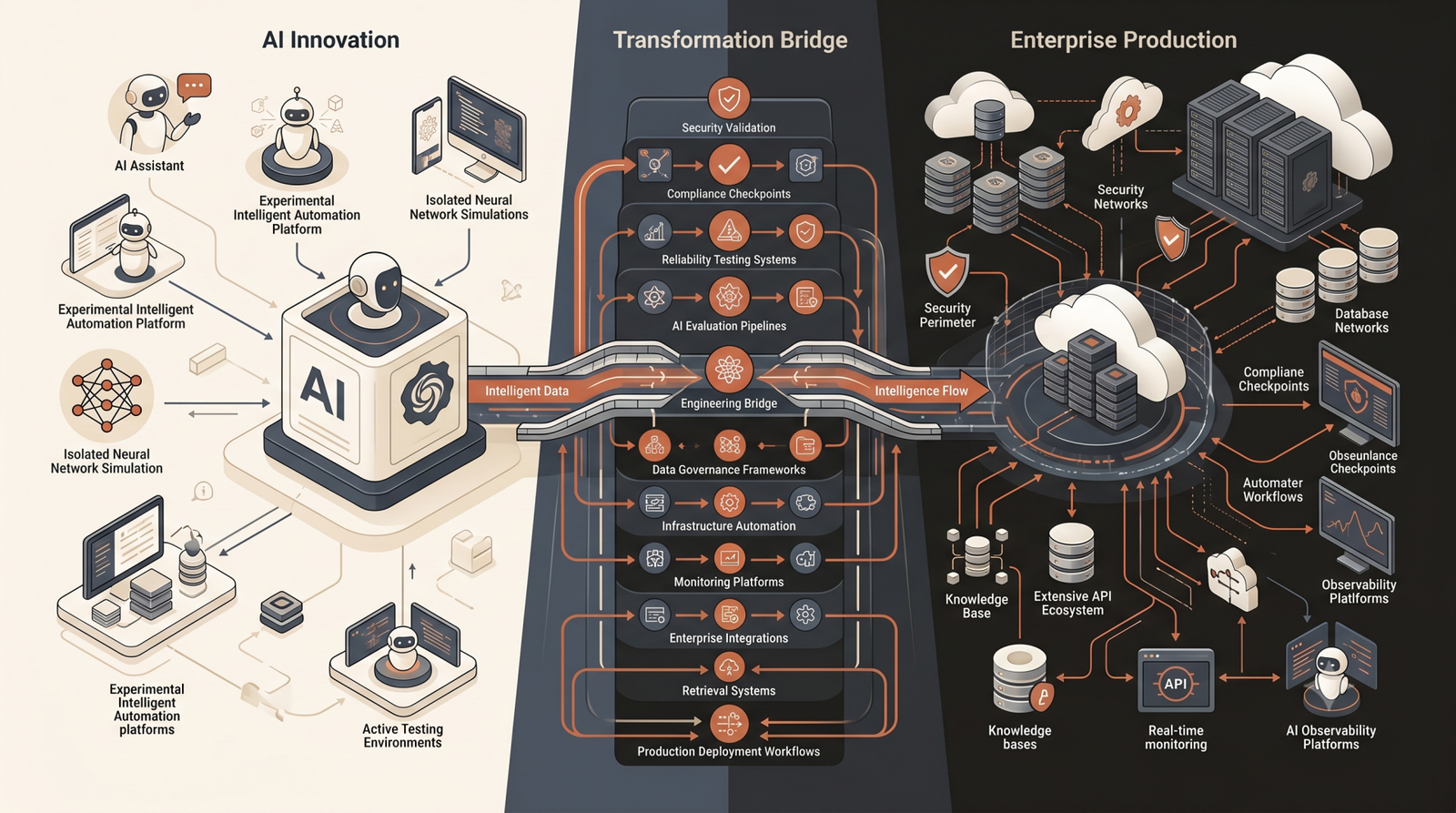
Building an impressive AI demo has never been easier. With a few API calls, an off-the-shelf framework, and a local vector database, a solo developer can string together a prototype that looks like magic in a controlled environment. But there is a massive chasm between a Jupyter notebook proof-of-concept and a high-availability enterprise system. When startups and enterprise teams attempt to push these fragile prototypes into production, the magic quickly degrades into latency spikes, hallucination loops, and catastrophic edge cases.
At Acadify Solution, we frequently audit AI systems that worked flawlessly for ten beta users but completely collapsed under enterprise load. The root cause is almost always the same: treating AI as a software feature rather than a complex distributed system. Production-grade AI requires Kubernetes-scale infrastructure, strict CI/CD pipelines, and rigorous reliability engineering. The moment your LLM integration hits real-world concurrency, naive architecture fails.
The Architecture Gap: Naive RAG vs. Production Systems
Most initial Retrieval-Augmented Generation (RAG) pipelines rely on simple semantic similarity. A user asks a question, the system queries Pinecone or PGVector for the top-k closest matches, and stuffs them into a prompt. In production, this approach consistently falls apart. High-dimensional vector space is noisy. Relevant documents get buried, context windows overflow, and the model inevitably hallucinates when forced to synthesize fragmented chunks.
Need MVP Development or AI Solutions?
Turn your idea into reality with Acadify. Fast, scalable, and built for enterprise growth.
Enterprise RAG requires a multi-stage retrieval architecture. Instead of relying solely on embeddings, we implement hybrid search systems that combine dense vector retrieval with sparse keyword matching (like BM25) deployed on highly available Redis or Elasticsearch clusters. But retrieval is only half the battle. Passing raw chunks to an LLM is a recipe for unpredictable output.
To ensure 99.99% reliability, we introduce semantic reranking layers before the context ever reaches the inference engine. By scoring and dynamically filtering the retrieved chunks based on strict relevance thresholds, we dramatically reduce token consumption and improve factual accuracy. This isn't just about getting better answers; it is about defending the system against behavioral drift and ensuring predictable compute costs.
Validating Reliability: The ASR Methodology
Standard QA engineering—unit tests and integration tests—cannot fully map the non-deterministic nature of large language models. A model that passes an evaluation suite on Monday might fail on Friday due to subtle API updates or shifting user behaviors. This is why Acadify AI Labs developed the AI System Review (ASR) methodology, an engineering-grade evaluation framework specifically designed for continuous production validation.
The first pillar of ASR is Context Engineering. We do not just test isolated prompts; we map the entire state machine of user journeys. We simulate how the system architecture manages context over deep, multi-turn conversations. If a user changes their intent midway through a session, the system must recognize the shift without dragging obsolete context into the current inference cycle.
Next, we execute Pressure Simulation and Failure Mode Analysis. We subject the application to sustained, high-concurrency interactions, injecting complex prompt sequences designed to trigger logic drift and security vulnerabilities. By capturing SFT traces and conducting adversarial training audits, we force the system to fail in our staging environments so it never fails in yours. We actively monitor hallucination rates and boundary violations, ensuring the deployment meets enterprise security and HIPAA-compliant standards.
Compute Economics and Model Routing
A hidden killer of enterprise AI projects is inference cost. Routing every user query to the most capable, expensive model is an architectural anti-pattern. Smart systems utilize dynamic model routing based on query complexity. At Acadify, as an Official Anthropic Registered Tier Partner, we architect our microservices to orchestrate this logic seamlessly.
For complex reasoning, deep synthesis, or highly sensitive financial calculations, the gateway routes the request to Anthropic Claude 3.5 Sonnet or Opus. However, for straightforward data extraction, intent classification, or basic summarization, the system automatically downgrades the request to Haiku or a smaller fine-tuned model running on dedicated instances. This architectural decision requires a robust observability layer to monitor routing accuracy, but the operational leverage it provides is immense.
Case Study: Rescuing a Fintech Enterprise AI Deployment
Consider a recent engagement with a mid-market financial services platform. Their internal engineering team had deployed an AI-driven support resolution engine built on Next.js, LangChain, and a monolithic backend. Within weeks of their soft launch, the system hit severe operational bottlenecks. Inference latency exceeded 12 seconds per query, GPU compute costs were bleeding their AWS budget, and worst of all, the chatbot began hallucinating regulatory compliance timelines.
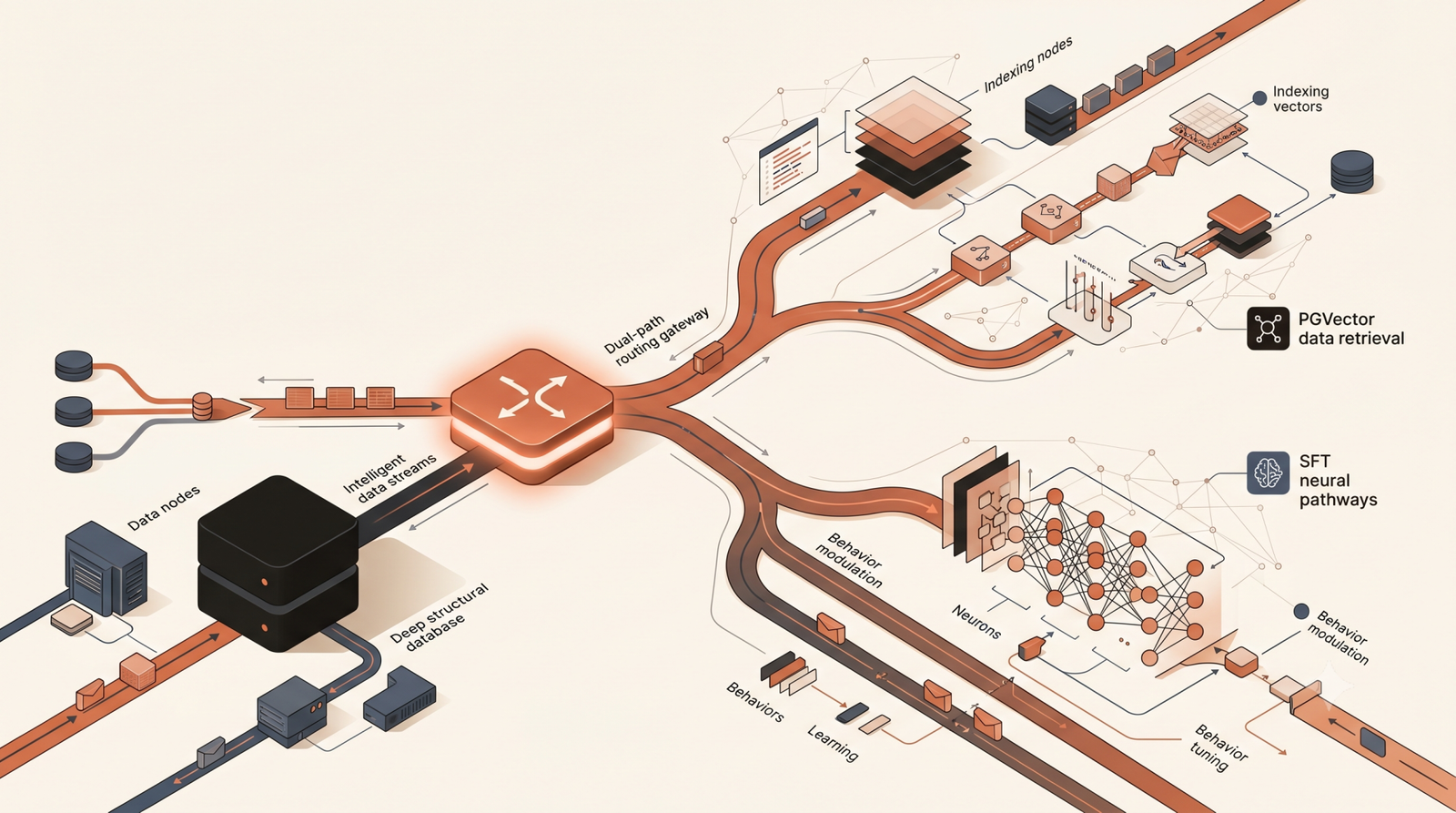
Our engineering team stepped in to rebuild the system from the infrastructure layer up. We stripped out the bloated framework wrappers and transitioned the architecture to a decoupled microservices model running on Kubernetes. We implemented a PGVector database optimized with custom HNSW indexing for instantaneous retrieval, and deployed a tiered routing gateway utilizing the Anthropic API.
Through our ASR methodology, we identified that 80% of the latency was caused by a redundant prompt-chaining loop. By restructuring the orchestration layer and implementing strict guardrails, the measurable outcomes were immediate. We reduced inference latency by 37%, lowered overall GPU compute spend by 42%, and eliminated compliance hallucinations, ultimately improving support resolution accuracy by 18%. The system scaled effortlessly during their next peak traffic cycle.
The Engineering Reality of AI
The tech industry is enamored with the idea of AI as magic, but at scale, AI is simply software engineering. It requires strict CI/CD pipelines, rigorous load testing, advanced caching strategies, and a deep understanding of distributed systems. Prototypes are easy to build, but production-ready, enterprise-grade AI demands architectural discipline.
If your team is struggling to move from an impressive local demo to a highly reliable, Kubernetes-scaled deployment, you need an engineering partner that understands the realities of production. Acadify Solution builds the enterprise infrastructure, scalable RAG pipelines, and strict evaluation frameworks required to deploy AI with confidence. Whether you need rapid CTO-level validation or a dedicated engineering team to stabilize your enterprise systems, our architects are ready to design your solution.
No comments yet. Be the first to share your thoughts!